Intel AVX-512 is the latest version of Advanced Vector Extensions. Since x86 instruction set was designed in the 1970’s there has been a drive to extend that instruction set so that the CPU can 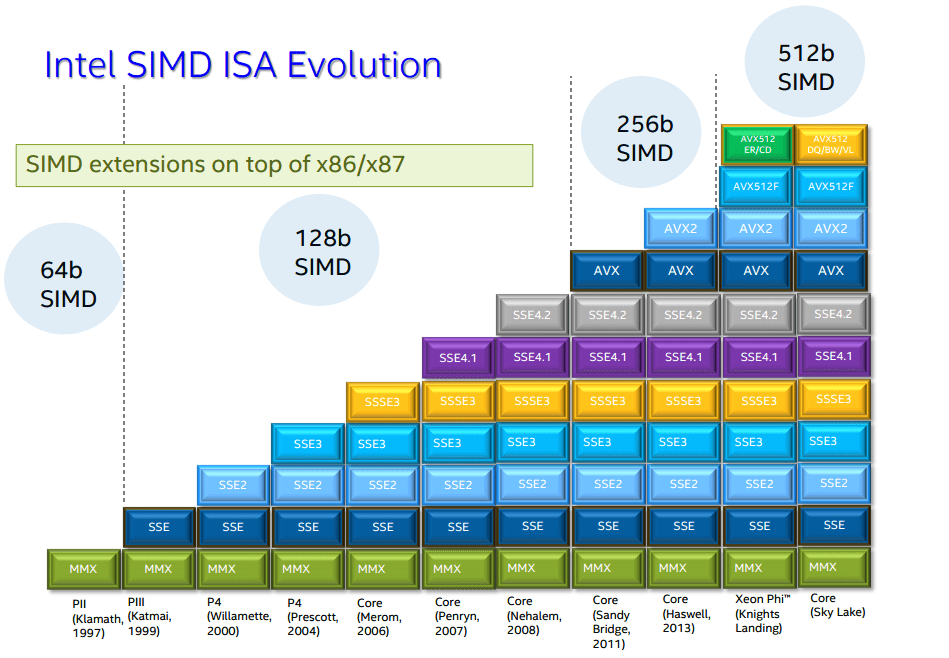 handle more and more tasks. This means that fewer and few special purpose add-on cards are required and that keeps cost, heat and electricity low. Previous extensions included MMX (Multimedia Extensions), 3D Now and SSE1-4 (Streaming SSID Extensions) and made thing like encoding video much faster.
handle more and more tasks. This means that fewer and few special purpose add-on cards are required and that keeps cost, heat and electricity low. Previous extensions included MMX (Multimedia Extensions), 3D Now and SSE1-4 (Streaming SSID Extensions) and made thing like encoding video much faster.
AVX-512 is a set of special purpose instructions are particularly useful in intensive tasks like:
- Artificial Intelligence,
- cryptocurrency mining,
- audio / video encoding
- development tools like Visual Studio 2017
- high performance computing
The original AVX1 came out in 2008 on Intel Sandy Bridge Core I Series CPU’s and was quickly added to Intel’s primary competitor AMD CPU’s.
 Intel AVX-512 is built into each core of Intel Xeon Scalable Processor cores released in mid-2017 and will also be available in some Intel Core I Series CPU’s to be release in 2018 code named “Canon Lake”.
Intel AVX-512 is built into each core of Intel Xeon Scalable Processor cores released in mid-2017 and will also be available in some Intel Core I Series CPU’s to be release in 2018 code named “Canon Lake”.
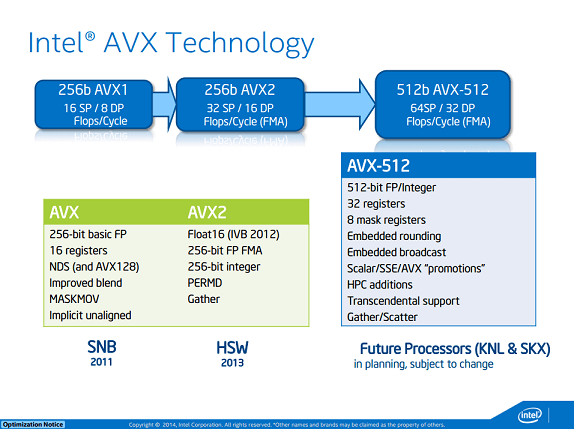
Like the Intel Advanced Vector Extension (Intel AVX) instruction set extension that preceded it, Intel AVX-512 allows a single instruction to perform a calculation on multiple values at once, and, as the name implies, it extends this capability up to 512 bits at a time. However, this is not all it does. New features make it easy to perform calculations that were not practical before. Masking lets you vectorize conditional code, embedded broadcast lets you use scalar values directly in calculations, embedded rounding control lets you control rounding or exceptions on a particular instruction without having to alter the control register, and new instructions perform calculations that might have taken dozens of instructions before… https://blogs.msdn.microsoft.com/vcblog/2017/07/11/microsoft-visual-studio-2017-supports-intel-avx-512/
 There are many different levels of AVX-512 so you need to be careful throwing the name around:
There are many different levels of AVX-512 so you need to be careful throwing the name around:
AVX-512-F: Foundational support. Required for all AVX-512 products. Anything advertised as AVX-512-capable must support AVX-512-F.
AVX-512-CD: Conflict Detection. Allows a wider range of loops to be vectorized. Supported on Skylake-X (Skylake-SP and Skylake-X use the same architecture).
AVX-512-ER: Exponential and Reciprocal instructions designed to help implement transcendental operations. Supported in Knights Landing.
AVX-512-PF: New prefetch capabilities. Supported by Knights Landing.All of the below operations were introduced with Skylake-X earlier this year:
AVX-512-BW: Byte and Word operations to cover 8-bit and 16-bit operations.
AVX-512-DQ: Doubleword and Quadword instructions. New 32-bit and 64-bit AVX-512 operations.
AVX-512-VL: Vector Length extensions. Allows AVX-512 to operate on XMM (128-bit) and YMM (256-bit) registers.The following instructions will be introduced with Cannon Lake, in addition to AVX-512-F, AVX-512-CD, and all three Skylake-X capabilities):
AVX-512-IFMA: Integer Fused Multiply-Add with 52-bits of precision.
AVX-512-VBMI: Vector Byte Manipulation Instructions. Adds additional capabilities not in AVX-512-BW.
https://www.extremetech.com/computing/257730-intel-may-deploy-avx-512-upcoming-10nm-cannon-lake-cpus
For more information on Intel AVX-512 you will definitely find these two posts interesting:



0 Comments