Deep Fakes are computer generated videos, typically of politicians or celebrities, saying things they did not say.
Most people first heard of DeepFakes in the spring of 2018 when comedian and film maker Jordan Peel produced this short video of former President Obama trashing US President Trump.
https://www.youtube.com/watch?v=cQ54GDm1eL0
In that video Peel made it clear it was him narrating the words and head movements while a high powered computer produced a very real looking video of Obama saying the words and using Peels facial expressions. This is the electronic version of a ventriloquist and dummy routine.
If you have ever wondered how they make these films but don’t have a degree in Artificial Intelligence, this is the article for you.
 The technology grew out of “filters” which you have probably played with yourself. In the case of “filters” a computer does some basic calculations like:
The technology grew out of “filters” which you have probably played with yourself. In the case of “filters” a computer does some basic calculations like:
- core facial recognition (today this is an easy feat to accomplish)
- the distance from the tip of your nose to the top of your upper lip
- the distance between the pupils of your eyes
- the color of your skin
- your hair line and much more
Today however, deep fakes can do much more than just correctly position a rabbit’s nose on top of your nose and move it perfectly in sink with your head movements. Deep Fakes use powerful machine learning algorithms to figure out all of the variables.
As soon as we said machine learning and algorithms, we know we lost a bunch of you so we will avoid that jargon in the rest of this article as we want to explain the process simply. You did not want to read something from essay services, sorry!
To make a Deep Fake, producers need three things:
- a few thousand still pictures of two peoples faces
- both the source speaker (i.e. Peel) and the target speaker (i.e. Obama) must be recorded at different angles saying different words
- typically this is accomplished by converting existing video into still pictures
- a powerful computer
- supercomputers used to be required but in 2020 all of the needed hardware is commodity grade and, in fact, it can be rented through the internet (i.e. think Microsoft Azure, Amazon Web Services…)
- software to decode the stills and generate new ones
- those new stills pictures are put together to make a new video
As explained, getting the pictures and the computer hardware is not difficult anymore. That leaves us with the last item, the software and that is where the real magic of Deep Fakes lies.
Software like DeepFaceLab and Adobe After Effects perform three key functions:
 Extraction: cut up video frames, detect the faces in each frame, then output tightly cropped images of each face
Extraction: cut up video frames, detect the faces in each frame, then output tightly cropped images of each face- Training: Use the extracted images to train itself to take an image of one person’s face and output an image of the other persons face with the same expression and shadows
- Conversion: Apply the training, to a specific video and output a new DeepFake

The interesting part here is the training process. The software first figures out what is different between the source and target images. So if Jordan Peel has the same color eyes as Barak Obama, it does not have to consider eye color as a factor. It looks at thousands of still pictures to make these determinations. If both the source and target person have very similar cheek bones, skin tone and hair line, it knows to ignore those characteristics in future calculations. The more similar people look, the faster and more realistic DeepFakes can be produced.
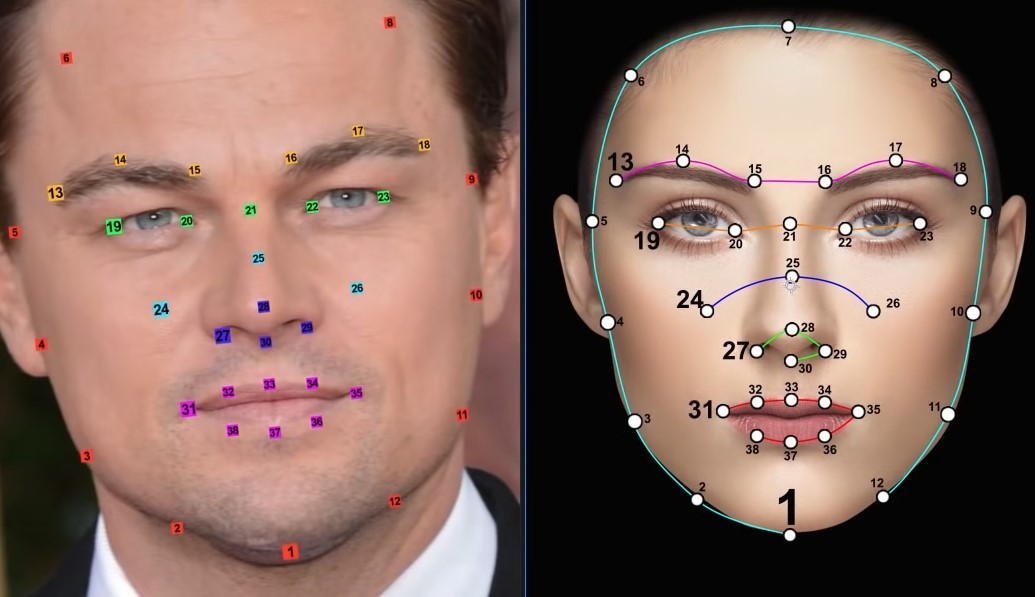 After it has figured out what needs to change, the software performs millions of calculations on what remains. Just like your social media video ‘filters’ that add expand your eye size or add a funny nose, the DeepFake software calculates distances between the remaining parts and as well as the shadows which is what techs call “illumination”.
After it has figured out what needs to change, the software performs millions of calculations on what remains. Just like your social media video ‘filters’ that add expand your eye size or add a funny nose, the DeepFake software calculates distances between the remaining parts and as well as the shadows which is what techs call “illumination”.
At this point you might think that the heavy lifting is done, but the systems are now smart enough to test and fix themselves.
Once the software has its calculations from both faces, it will build a new face and then compare what it built to the original still images that it made the calculations on. The software will then find the differences, or what you and I might call mistakes, and adjust its calculations to remove them and build new, more accurate faces.
That last step of building a new face and checking it against the faces that were fed into the system, is something that can and is done potentially millions of times. Each iteration produces a better output.
This means that DeepFake producers with more time and/or more money (for more powerful or faster computers) can produce extremely lifelike images and then assemble them into a video that you will find very hard to dispute as not being authentic. Who has such resources? Lots of people. Governments like China, Russia and the United States, the mob, political parties, tech companies, professional hackers, and movie studios can all easily build DeepFakes.
But wait, remember we said at the start that you can rent the hardware for very little money and produce amazing product. Well, the good people are ARS Technica did just that earlier this week. They produced the video below in a few days with only about $500, in which they put the face of Star Trek’s Data character onto Mark Zuckerburg appearing before the US Congress.
It is far from perfect but ARS Technica was not trying to fool viewers. They were just trying to show that with a tiny amount of money and time anyone with slightly more than basic skills can produce something impressive.
Take a look at this video from TED and the BBC explaining the process:
In summary, the world of tomorrow and even today is one in which you can no longer believe your eyes and ears. If you get your news from Facebook and Twitter, you are in for a rough ride. It is now time to deeply consider who is providing your news. If it is not someone with a very long track record of fact checking like The Guardian, TED, BBC, 60 Minutes or the New York Times, you are going to be fooled by this amazing tech.
You might also be interested in our article What is Machine Learning vs Deep Learning vs Reinforcement Learning vs Supervised Learning?



2 Comments
Anonyomous · December 9, 2022 at 8:53 pm
This is fire i like the way that you explained how it worked. The included videos also helped.
How Convert 2D Videos to 3D Videos in 2023 – Up & Running Technologies, Tech How To's · January 5, 2023 at 9:24 pm
[…] businesses that invest in this technology stand to gain several advantages. For starters, 3D videos are more engaging and exciting for viewers. Additionally, they can help businesses break through […]